用于查看mysql锁状况的指令。
select * from information_schema.innodb_locks; #锁的概况
show engine innodb status; #InnoDB整体状态,其中包括锁的情况
默认事务控制
mysql默认 autocommit 模式下,每一句sql语句都会以一个事务隐式执行。
事务是不是会自动加锁?
1、所有写操作(insert | delete | update)都会自动加 写锁 (for update),所以在事务中执行写操作,到事务提交前,都会对相应数据处于写锁状态。
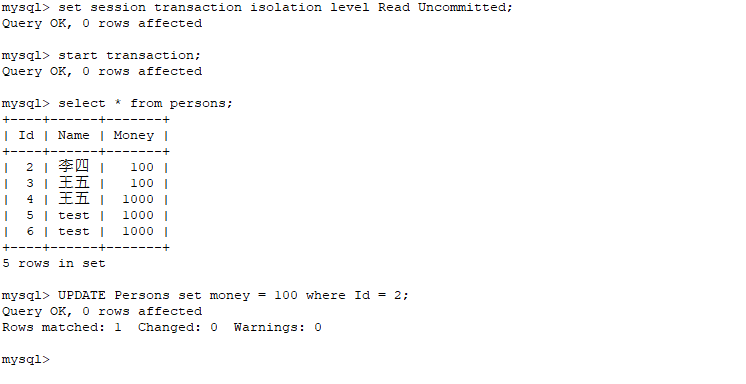


2、只有事务隔离级别(Serializable)下,读(select)操作才会自动加 读锁(lock in share mode,好像读锁也就这个地方用到了)
repeatable read 隔离级别下测试
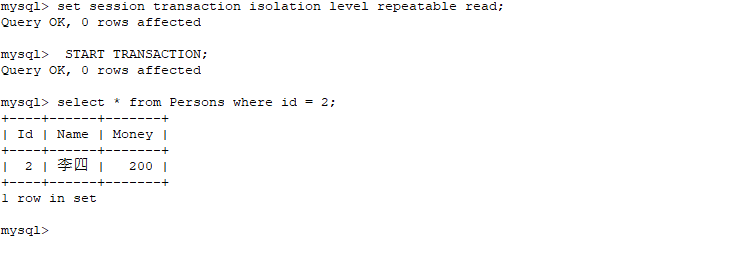
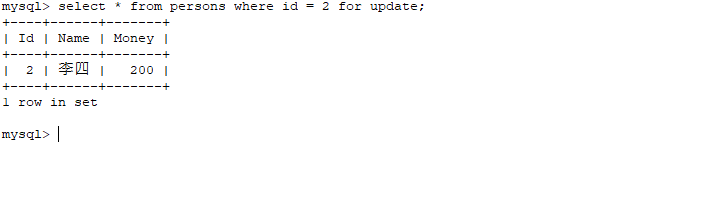
Serializable 隔离级别下测试



事务的不同隔离级别是如何实现的?
mysql的mvcc(多版本并发控制, 主要靠这个) + 锁机制(就Serializable 用了读锁)。
基本知识(下面的规则是针对repeatable read 隔离级别,不过其他两个级别应该也是同样的方式,微调逻辑)
- 每个开启的事务,会有一个tx_id,是不断自增长的,后面开的事务比前面开的事务大。
- 每次开启事务都会开启一个新的ReadView。ReadView里包含:
- 当前活跃的事务id列表
- 创建者的事务id
- up_limit_id( 表示生成ReadView时 ,当前系统中活跃的读写事务中最小的事务id )
- low_limit_id(表示生成ReadView时 , 系统中应该分配给下一个事务的id)
- 关于可见性的规则:
- 读某一行数据的时候,如果发现他的 事务id < up_limit_id,可见。
- 如果发现数据的 事务id≥low_limit_id,不可见。
- 如果发现数据的事务id在列表范围内
- 如果是id集合中的,不可见
- 如果不在id集合中,可见
案例:
repeatable read 隔离级别下,开启事务10, 创建readview [ 7, 8, 10 ]。表明当前有这3个活跃的事务。
up_limit_id=7,low_limit_id=11
根据可见性规则,如果 事务id = x,
x < 7 || x = 9 为可见;
x≥11 || x==7 || x==8 || x==10 为不可见(通过数据的undo log 找到上一个版本的数据,继续对比事务id。递归到可见为止)
脏读(读取未提交):未提交的数据是在当前事务创建后更新而未提交的,所以事务id肯定要么大于x, 要么属于 readview 列表。所以可以免除。
不可重复读(读已提交):先读取旧数据,然后当然活跃事务提交数据更新,再次读取。新的事务id也必定是大于x , 或者属于 readview 列表。可以免除。
幻读:同上。
什么时候该手动加锁?
事实上我们只需要合理的利用mysql的事务即可,基本上不需要手动去对数据加锁。
唯一能想到状况是比如你在事务中先读取用户余额,再根据余额进行运算,然后存储新的余额。
select * from persons where id = **;
my_balance = 运算(balance);
update persons set balance = my_balance;
这种情况下需要先对余额进行锁定。
但是事实上我们大部分情况会直接用 update balance = balance - 100 这种方式,是不需要去手动加锁的。
Next-Key Locks
mysql 默认的隔离级别 repeatable read 下,除了行锁(基于索引)外,还存在间隙锁,两者组合成 Next-Key Locks。
-
对唯一索引 加锁:
进行等值检索,只存在行锁。
进行范围加锁(select * from persons where id >100 for update | update set *** where id >100 ),会锁定id > 100 的数据和间隙。
-
对非唯一索引加锁: 等值或范围检索,都会锁定 数据 和 间隙。
-
非索引加锁:全表记录锁定,全表间隙锁定。
参考文件:
MySQL 事务的实现原理,写得太好了!_Java技术栈,分享最主流的Java技术-CSDN博客
Mysql MVCC 原理 low_limit_id ReadView_stevewong的专栏-CSDN博客