创建一个测试表
CREATE TABLE `test` (
`id` bigint(20) NOT NULL,
`number` bigint(20) NOT NULL,
`title` varchar(50) NOT NULL,
`content` varchar(255) NOT NULL,
`sort_num` int(11) NOT NULL DEFAULT '99'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `test`
ADD PRIMARY KEY (`id`)
ALTER TABLE `test`
MODIFY `id` bigint(20) NOT NULL AUTO_INCREMENT,
COMMIT;插入30w条测试数据,最后看上去大概下面这样。
到目前为止,系统没有创建任何索引(除了主键)
1、测试 简单数据查询
SELECT * FROM `test` where number = 123456 # 0.2-0.9S
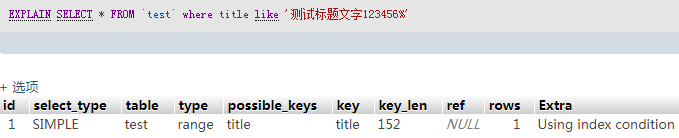
SELECT * FROM `test` where title = '测试标题文字123' # 0.2-0.3S创建索引后 ,再次测试简单查询
SELECT * FROM `test` where number = 123456 # 0.0006S
SELECT * FROM `test` where title = '测试标题文字123' # 0.0004S解析sql语句
EXPLAIN SELECT * FROM `test` where title = '测试标题文字123'
2 测试范围查询 (有索引的情况下)
SELECT * FROM `test` where number > 123 # 0.4S
SELECT * FROM `test` where number > 123456 # 0.4S
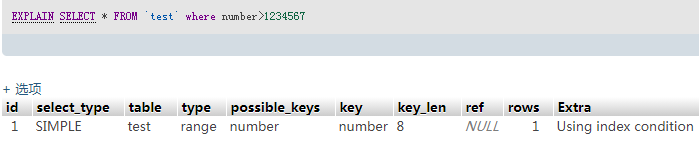
SELECT * FROM `test` where number > 1234567 # 0.0004S
SELECT * FROM `test` where title like '测试标题文字1%' # 0.4S
SELECT * FROM `test` where title like '测试标题文字123%' # 0.01S
SELECT * FROM `test` where title like '测试标题文字123456%' # 0.0004S
SELECT * FROM `test` where title like '%测试标题文字1%' # 0.4S
SELECT * FROM `test` where title like '%测试标题文字123%' # 0.3S
SELECT * FROM `test` where title like '%测试标题文字123456%' # 0.3S后面3条因为 like 前面加了%所以没法走索引,所以时间都是属于全表检索的时间
1、2、4 属于检索结果数量(mysql自己预估的数量)占数据表数量总比例过大(具体多少,我也不知道,大概是15%左右吧),导致mysql觉得走索引不如直接全表检索,所以效率和全表检索一样
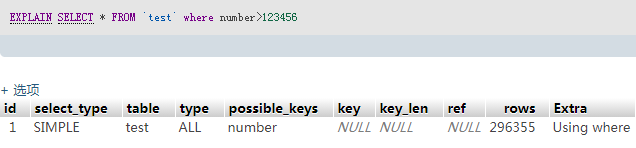
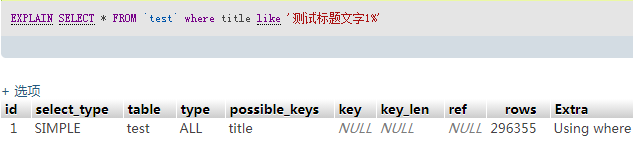
3、5、6 走了索引,效率大概提升了100-1000倍(因为索引表读完后还需要回表读取数据,所以范围查询的查询结果数量也会影响sql语句执行时间)

3 limit查询
SELECT * FROM `test` limit 0,20 # 0.0004S
SELECT * FROM `test` limit 1000,20 # 0.0008S
SELECT * FROM `test` limit 100000,20 # 0.07S
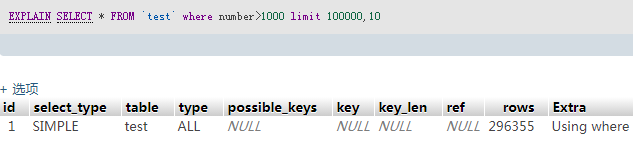
SELECT * FROM `test` where number>250000 limit 0,20 #0.02S
SELECT * FROM `test` where number>250000 limit 1000,20 #0.03S
SELECT * FROM `test` where number>250000 limit 100000,20 #0.5S
SELECT * FROM `test` where number>10000 limit 0,20 #0.03S
SELECT * FROM `test` where number>10000 limit 1000,20 #0.03S
SELECT * FROM `test` where number>10000 limit 100000,20 #0.8S1、2、3走的主键,所以速度是最快的
剩下走的number索引


接下来我把number索引删除
SELECT * FROM `test` where number>10000 limit 0,10 # 0.0004S
SELECT * FROM `test` where number>10000 limit 1000,10 # 0.0008S
SELECT * FROM `test` where number>10000 limit 100000,10 # 0.07S
SELECT * FROM `test` where number>1000 limit 0,10 # 0.0003S
SELECT * FROM `test` where number>1000 limit 1000,10 # 0.0007S
SELECT * FROM `test` where number>1000 limit 100000,10 # 0.07S神奇的事情发生了,居然比有索引更快
原因主要有几点:
1、 limit 10000,20 虽然是从10000条开始抓20条回表读取,但是计算机比较笨,他会从头开始读索引,直到读到10000,所以 limit 10000,10 数据遍历行数其实是10010 而非10;这也体现在limit头越大,执行速度越慢上(可以通过每次limit时 带上number>上次的number最大值来解决)
2、因为测试表数据比较少,所以即使走全表读取也并没有花费很多时间(毕竟走number索引也是从头开始读取索引),但是正式使用的数据表数据相对复杂,跑全表读取,运气好的话,你limit的数据在前几万行里,一下读出来了,运气不好就完蛋了。所以 我们还是需要去做索引并进行limit的优化。
4 组合索引
先创建一个组合索引
ALTER TABLE `test` ADD INDEX( `number`, `title`);那我们现在就有 number索引 title索引和 组合索引(number、title)
组合索引基本测试
SELECT * FROM `test` where number=1000 AND title='测试标题文字1234'
同时检索 number title的时候 ,很不给面子的直接走了 title索引;
不过也对,因为我title都是唯一的。mysql会对 where条件进行检索优化,以达到最好的检索效率。所以直接忽视了我的number索引和联合索引。
我们把数据库调整一下,让索引基数变小。
UPDATE `test` SET `number`= floor(rand()*10000),`title`= CONCAT('标题',floor(rand()*10000)) WHERE 1然后再来测试一下
SELECT * FROM `test` where number=1000 AND title='标题1000'
这下终于不负众望的走的组合索引了。
组合索引范围查询测试
EXPLAIN SELECT * FROM `test` where number>8000 AND title='标题1000'
这条走的是title单索引,因为我们 number>8000 属于范围查询,所以根据最左匹配原则,所以如果这种情况还用符合索引的话,只能命中 number,不如title的命中率高,所以走了title索引。
EXPLAIN SELECT * FROM `test` where number=9000 AND title like '标题1%' # 0.0005S
如果我们将范围查询放到索引的第二个查询字段上,就可以用到符合索引了。
覆盖索引
SELECT * FROM `test` where number=9000 AND title like '标题%' #0.02S
SELECT title,number FROM `test` where number=9000 AND title like '标题%' #0.0004S因为title、id、number其实都在索引(也可以理解为一张表)里了,所以当我们select 的条件为这几个时,不需要回表,速度会得到明显的提升
5 mysql 的 order by
order by 要和 where / limit 一起使用才能用到索引
(用于也要考虑检索结果行数对于数据表总数的占比,如果太高还是会直接走全表文件检索)
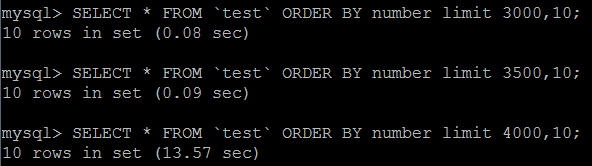
SELECT * FROM `test` ORDER BY number limit 10000,100 #5S
SELECT * FROM `test` ORDER BY number,title limit 10000,100 #0.7S因为只有用order by,所以并没有用到索引(至于为什么第2条明明排序条件更多,也没有用到索引,但是检索时间缩短了10倍,我想不出来为啥~~)

order by + limit
在 遍历数据行数(3000)/数据总数(300k) ≈ 1% 左右以下可以用到索引,好吧 ,为什么是这样我不太明白,和之前的 15%差别很大
order by + where
在 遍历数据行数(55000)/数据总数(300k) ≈ 10-15% 左右以下可以用到索引
SELECT * FROM `test` WHERE number>9000 ORDER BY number
SELECT * FROM `test` WHERE number>8000 ORDER BY number
order by + where +limit
这个 在 遍历数据行数(150000)/数据总数(300k) ≈ 50% 左右以下可以用到索引
SELECT * FROM `test` WHERE number>100 ORDER BY number limit 10000,100 #0.3S
SELECT * FROM `test` WHERE number>100 ORDER BY number,title limit 10000,100 #0.3S

order by 使用联合索引
a) where的索引优先级高于order by,
1 where和orderby 分别存在索引,where索引会优先使用(理论上,但是测试结果和理论不符合)
SELECT * FROM `test` where title='123' ORDER BY number ASC,title DESC limit 100,10
意外测试结果
索引字段-sort_num - 默认值为99 几乎都是99,所以开始就没想过要做为索引,命中率太低,不符合我们通常对索引的认知,但是本着试一试的心态把这个字段设置为索引,下面的sql语句检索时间从3S降为0.03S
SELECT * FROM `test` ORDER BY sort_num ASC limit 10000,10
更为意外的是,这个命中率很低的 索引 优先级更超过了 命中率相对较高,且在where条件上生效的number字段
EXPLAIN SELECT * FROM `test` WHERE number>9000 limit 1000,10
EXPLAIN SELECT * FROM `test` WHERE number>9000 ORDER BY sort_num ASC limit 1000,10
单纯的limit语句不用去考虑索引命中率,这我倒是理解,毕竟limit和where不同,只需要在索引数据(另一个b+树)上进行二分查询获取固定位置区间的数据。
但mysql会将索引优先级提高到超过where字段的优先级,实在难以理解
时间有限,没有再往深处研究了,希望后面能弄明白,可能是我哪里弄错了
2 如果希望where和ordeby 索引一起使用,可以做成联合索引;但是需要把where的索引字段摆在联合索引前面;
- 如:我们有联合索引(number,title)
SELECT * FROM `test` WHERE title='测试标题123' ORDER BY number
SELECT * FROM `test` WHERE number=123 ORDER BY title
其实很好理解,我们查询的结果集其实是通过where查询出来以后,才能进行排序的。而非先排序在查询。
b) order by 联合索引双向排序 不支持(8.0貌似支持了 ,没测试),而且双向索引 会让单独的排序字段索引失效,所以尽量不要使用
mysql5.7及以下版本 不支持 order by number asc,title desc 这种(符合索引(number,title)),只能走同向
SELECT * FROM `test` WHERE number>9000 ORDER BY number ASC,title ASC
SELECT * FROM `test` ORDER BY number ASC,title DESC limit 100,10
第二个sql语句用了 number ASC + title DESC, 既无法使用到 联合索引,也无法用 number的独立索引